
System-level Security
The security overview page shows a summary of findings, their change, age and estimated severity.
The different elements in this page are:
- Findings shows a count of the current number of findings. Below it is the number of changes, based on the source code comparison period. This range be changed in the top right as usual. The note “Also showing … resolved findings and … informational findings” means that on top of this number, more findings are shown below. This is relevant for estimating activity surrounding these findings, such as fixing security findings or marking them as false positive.
- Activity shows a breakdown of this number. A mouseover on the Activity barchart will show the following:
-
The Findings Age tile gives an indication how long findings are known.
-
The CVSS Severity tile summarizes a breakdown of findings according to CVSS severity ratings. A mouseover on the barchart will show the exact number of findings. A mouseover on the CVSS severity barchart shows the number of findings with that CVSS severity category.
Context and meaning of CVSS security metrics: from asset to risk
CVSS (Common Vulnerability Scoring System) is a security-industry standard metric on a 0-10 scale, to indicate how severe a security issue may be. It does not signify a definite security problem, nor does lack of CVSS (or 0 score) imply security. This uncertainty is at the core of system security and mostly dependent on context.
It is important to make some distinctions by defining the elements that are necessary to properly interpret the meaning of these numbers. To simplify matters, consider the following non-exhaustive definitions:
- An asset is something of value. An asset exists in context, like the way that a system is connected to the outside world.
- A weakness (or flaw) is a (security-relevant) deficiency. In our context, a weakness may be catalogued as a CWE see also section on CWEs below. A weakness may be exploitable or not.
- A vulnerability is an exploitable weakness (by a threat). In our context, a vulnerablity may be catalogued as a CVE. A vulnerability may be actually exploited or not.
- A threat is an event/condition that causes undesirable/adverse effects to something of value (often described as assets). A threat may manifest or not.
- A risk is a possibility of harm, a chance that an undesirable event may occur. Typically it is understood as a function of probability and impact. In this context it is useful to consider that a risk involves an asset, a threat and a vulnerability. A risk may occur or not.
Sigrid’s CVSS score of Raw findings signify “potential severity”
We may use “risk” a lot in colloquial language, but in this context of system security, a lot has to co-occur before a risk manifests, as can be seen above. This is relevant in reading the CVSS scores in Sigrid, because without a triage and a verification context, CVSS does not mean vulnerability or risk. CVSS scores, even when unvalidated, are a useful indicator. Generally, triage/analyze raw security findings, you would follow the CVSS scores in descending order from “potentially most severe to - least severe”.
Sigrid’s CVSS scores are based on a CWE benchmark
CVSS originates in research done by the US government’s National Infrastructure Advisory Council (NIAC), further developed by the Forum of Incident Response and Security Teams (FIRST). CVSS is strongly associated with the administrations for CWEs and CVEs. CWEs are part of the authoritative list of weakness types known as the “Common Weakness Enumeration” by MITRE MITRE CWE website. For CVEs, see the National Vulnerability Database(NVD)). A CVE always contains a CWE, while the opposite is not necessarily true (e.g. a weakness that has not been shown to be exploitable). CWE has a hierarchical structure, so higher-level weaknesses implicitly contain lower-level ones.
Elaboration on the CWE benchmark calculation
The core idea of the CWE benchmark is that, since CWEs, CVEs and CVSSs are related, we can use CVSS data associated with CVEs to come up with a score for CWEs. A benchmarked CWE score (presented as CVSS in Sigrid) consists of the averaged CVSS scores of all linked CVEs. In this calculation process, a weighted mean is applied to Impact and Exploitability (these are part of the CVSS “Core metrics”). This configuration puts more weight on relatively infrequent, but severe vulnerabilities. In case that the size of the dataset is below a certain threshold, an algorithm will crawl through the CWE hierarchy to find more relevant data points.
For each CWE, we build its CWE hierarchy tree and determine their respective CVEs of the last 5 years and the CVE’s typical CVSS estimations by security experts. This is a benchmark of expert judgements. Since context is a large factor in the severity of a security issue, the CVSS scores assigned to CWEs are further split by their attack vectors (this data is available since Attack Vector [AV] is part of the CVSS calculation). This split allows to make a mapping on this technical context, which should be administered in Sigrid as Deployment type metadata (see metadata page, specifically the GUI to do this in Sigrid itself). This metadata emulates CVSS’ “Environmental metric group” and provides important context to interpret its scores. If this metadata has not been set, Sigrid conservatively assumes “public-facing”, hence the most exposed type of deployment. All the different deployment type options (as other types of metadata) can be seen on the Sigrid API metadata end point page, specifically the Deployment type section.
CVSS scores in Sigrid
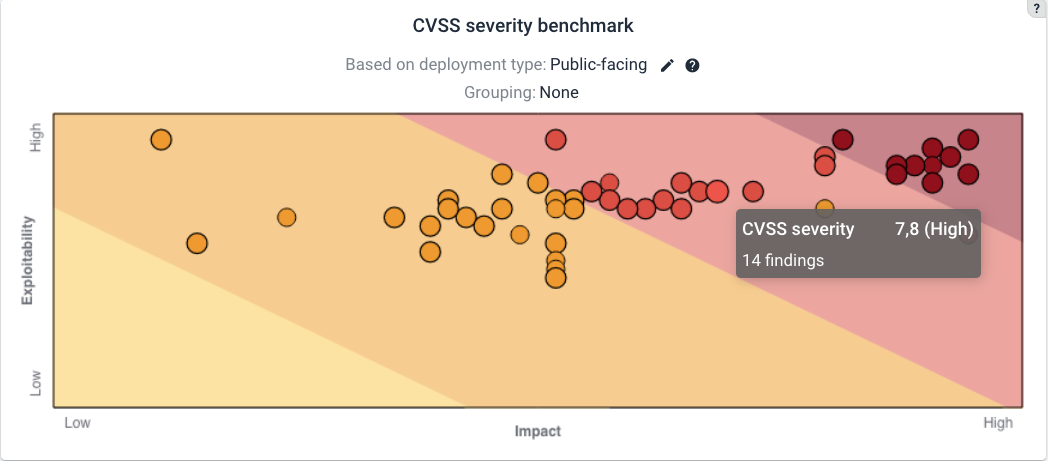
 The CVSS map adjusts to the filter that you may have used.
The CVSS map adjusts to the filter that you may have used.
Based on the CVSS score of findings, they are marked and colored ranging from “Information”, “Low”, “Medium”, “High”, “Critical”.
![]() Information: a CVSS score of “0”. These include anti-patterns that may not have a direct security impact but can still be significant.
Information: a CVSS score of “0”. These include anti-patterns that may not have a direct security impact but can still be significant.
![]() Low: CVSS score between 0 and 3.9.
Low: CVSS score between 0 and 3.9.
![]() Medium: CVSS score between 4 and 6.9.
Medium: CVSS score between 4 and 6.9.
![]() High: CVSS score >between 7 and 8.9.
High: CVSS score >between 7 and 8.9.
![]() Critical: CVSS score 9 or higher.
Critical: CVSS score 9 or higher.
To have an idea of what a certain CVSS score approximates, see NIST’s current 3.1 calculator or a calculation preview of the to-be-released CVSS 4.0). Note that an earlier CVSS version 2 did not include a “Critical” vulnerability category.
Different statuses of security findings
These are the different statutes of findings. The status “Fixed” will be applied automatically if a finding is resolved. See FAQ:Fixed issues are auto-detected. The other statuses can be set. They are similar to those used for system maintainability refactoring candidates.
- “Raw” means “not yet verified” where “Refined” ones mark that a finding has been confirmed manually. Inversely, a finding can be set as “False positive”.
- “Will fix” signals the intention to fix it, while “Risk Accepted” does not.
Different possible grouping of security findings
Different views can be selected in the left menu. security models. The menu selector on the left you to easily toggle between the different models in one view.
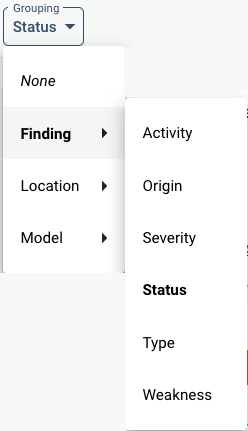
Note that here, the menu’s category in bold is the currently chosen grouping. Therefore, below, under the column “Description”, different statuses are shown. Because “Grouping” means that Sigrid will show you a summary, the number of findings are shown on the right column under “Findings”, such as [C]1, [H]1, [M]99+ and [I]99+. These abbreviate the severity of the findings based on their CVSS score, and their count. You can click on those for a listing of the detailed findings. See also the CVSS elaboration above.
In the Grouping menu in the top left under “Finding”, the following types of grouping can be set:
- “Activity” groups according to “New”, “Recurring” or “Resolved”.
- “Origin” refers to the originating tool of the finding.
- “Severity” orders on level of severity (based on CVSS).
- “Status” lists the statuses as mentioned above.
- “Type” shows a specific list of vulnerabilities. This is especially useful for technical analysis, since sometimes, a whole category/type of findings may be set to “False positive” (also, see below in the prioritizing section).
- “Weakness” orders on type of weaknesse (based on MITRE’s CWE database). Weaknesses are defined somewhat higher level than “Type”.
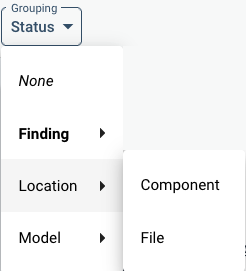
In “Location”, either “Component” or “File” grouping can be chosen. The Component group follows the maintainability grouping in components. Findings may fall outside of that grouping because of exclusions. Then they will show under the “Other” component. Examples might be binaries or package manager configuration files, which would be excluded for maintainability analysis and therefore not fall into a component for the purpose of maintainability calculations.

Under “Model”, different Models can be used to map findings on. This is in practice mostly a matter of preference or specific auditing requirements. Next to popular security models, SIG has developed its own model based on the ISO 25010 standard, which can also be chosen. These are based on the SIG Evalution Criteria Security.
A note on seeing the same file/finding multiple times
- A specific finding is counted once, but it may be visible in multiple views. This could be because e.g. there is certain overlap in classification of the model that you have chosen as a view.
- A specific line may be counted multiple times if it refers to multiple CWEs: a count is applied for each possible security risk. See also security FAQ elaboration on multiple views of the same finding.
Analyzing security findings
You can group and sort the detailed view of security findings. The sorting offers you the following.
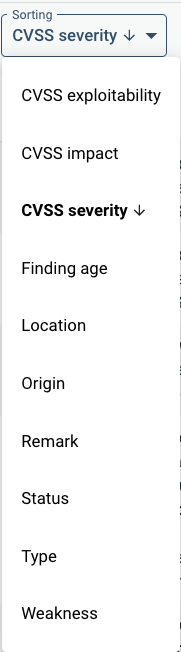
Below an example of a list of detailed findings with no grouping.
In the top left you can see that the findings are not grouped. Therefore each finding is shown individually. Below, the “Grouping” menu under “Sorting”, sorting is set to CVSS severity. Therefore the highest risk findings are shown above. Note that for example the first two findings are Maven dependencies. These originate from Open Source Health.
If Remarks have been registered, they can be seen in the far right column with a mouseover or clicking on the text balloon. An example of a mouseover is shown here.
If you click on the finding, the source code of the finding will be shown with its details. Details such as Status, finding age, Origin (scanning tool), File location, Remarks (if available) or audit trail are all viewable here.
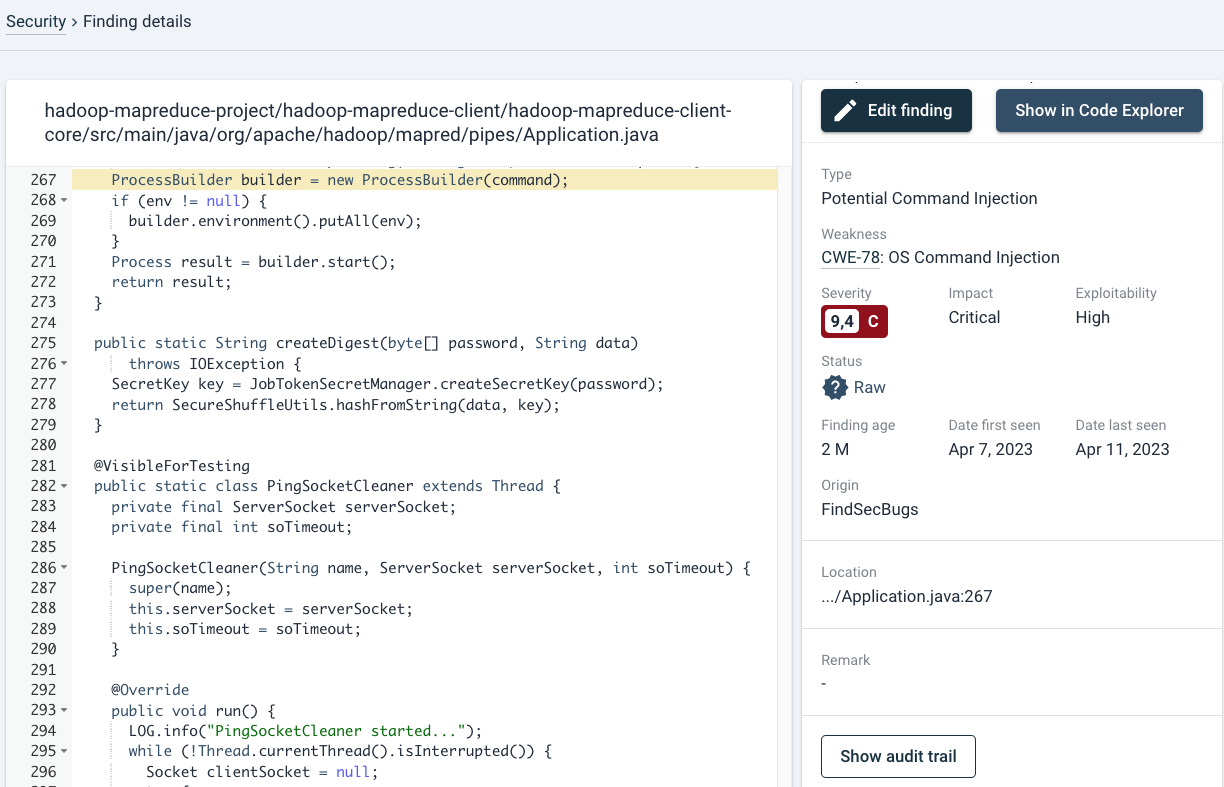
In the left panel, the specific line is highlighted in yellow, where a possible vulnerability may exist (in this case, OS injection). For details on e.g. the right panel, see Open Source Health-analysis section. Extra information such
Analyzing security findings: Dependency example (based on Open Source Health)
As above, starting from the findings overview: if you click on the finding, the source code of the finding will be shown with its details.
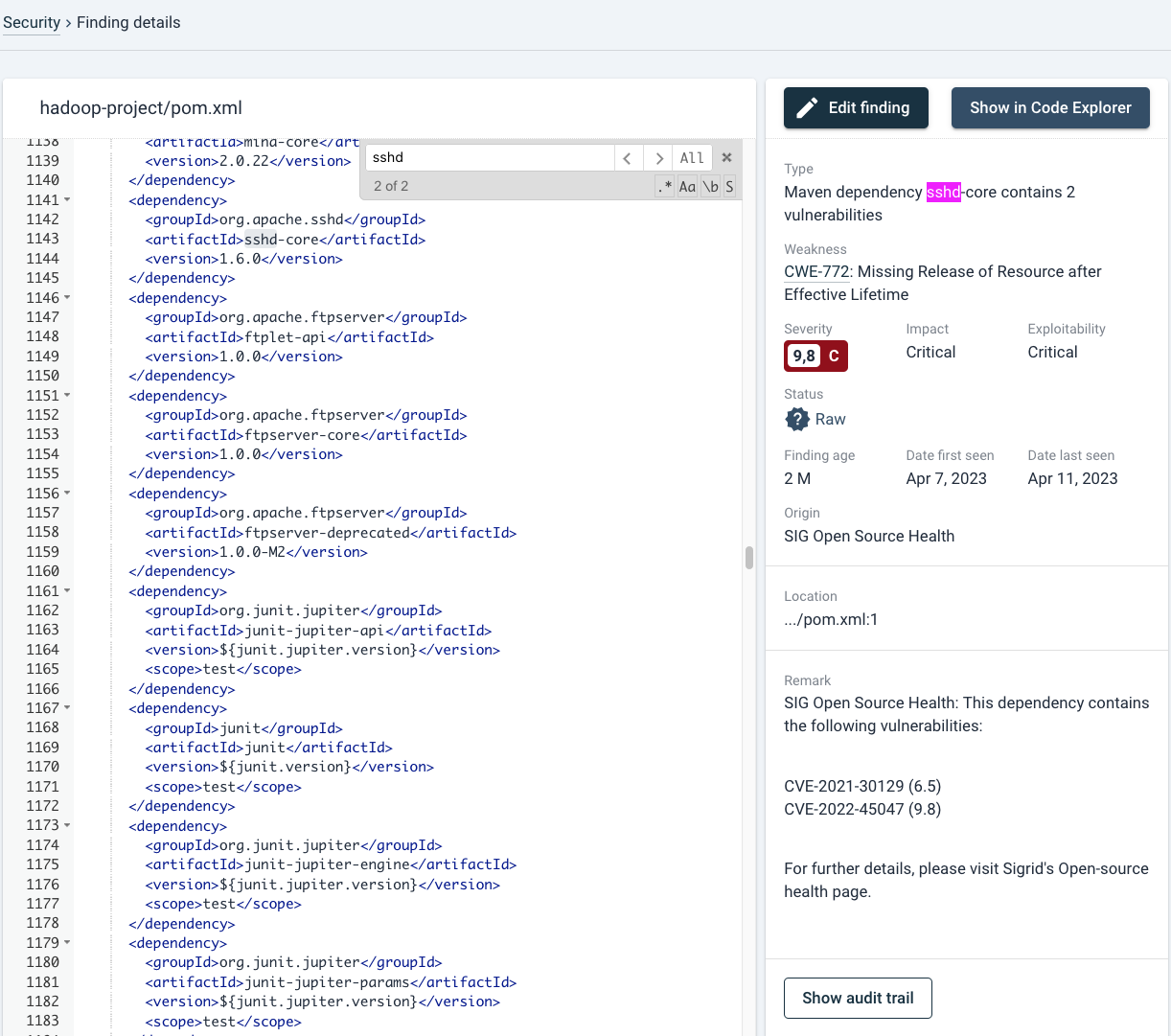
In case that the relevant line is not highlighted in yellow (this sometimes occurs in package management files), you can search within the file with cmd+f/ctrl+f. By default your browser takes precedence for this shortcut and therefore will try to search the page. You therefore need to move mouse focus to the left pane by clicking on the source code area or tabbing to the element first. You can use regular expressions if you wish so.
On the right side of the page, all details surrounding the finding are shown.
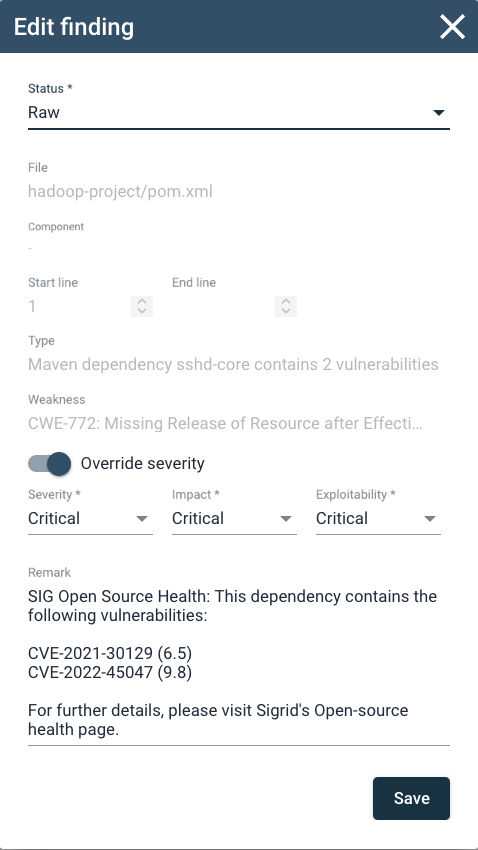
Changing a finding’s status and audit trail
 In the top right, the Edit Finding button allows you to change e.g. its Status and Severity
In the top right, the Edit Finding button allows you to change e.g. its Status and Severity
In this case, because this is an automatically scanned dependency by Open Source Health, e.g. changing its status to “false positive” will not necessarily remove the finding indefinitely. As long as the OSH tooling finds the same result, it will return. See also this specific case in the Security FAQ. The same holds for the “Remark”. Findings by Open Source Health* automatically add the type of vulnerability and vulnerability (CVE) reference. Remarks can also be adjusted manually. Any user can edit remarks or other characteristics. This could also be a SIG consultant, depending on your specific Sigrid agreement.
An audit trail can be seen when clicking the “Show Audit Trail” button. In case of changes, multiple entries will be shown with their respective usernames and dates.

CWE and its link with CRE (Common Requirement Enumeration)
If available, the relevant CWE will be shown. The CWE link in the security finding will refer you to the OWASP Common Requirement Enumeration (CRE) page. This will show the CWE in context. SIG has been an active and proud contributor to this project in close collaboration with the world’s application security authority OWASP (Open Worldwide Application Security Project). CRE is an open source security reference knowledge base, a nexus between OWASP’s initiatives and relevant, authoritative security reference documents originating in MITRE, NIST and ISO.
An example of openCRE is shown below.
Linking to Code Explorer
On the top right you can show the code in the “Code Explorer”, which will show you the code’s context and related findings. See also Code Explorer.
A general, typical strategy for processing security findings
Especially when Security is enabled in Sigrid for the first time in your system, the number of findings may seem overwhelming. Therefore, filtering out false positives is your first concern. That will give you a more accurate view of the system’s risk exposure. And then you may set priorities, and writing explanations or recommendations for findings that need attention.
Threat modeling as a requisite for interpreting security findings
The absolutely most solid way to approach security is to start by threat modeling. This takes you a step back of all the technical findings. A threat modeling effort should involve brainstorms, whiteboarding and Data Flow Diagrams to reach a basic system threat model and its associated security risks.
There is wide availability of training and instruction regarding threat modeling e.g. OWASP’s Threat Modeling Cheat Sheet or the Threat model Wikipedia page, where the Threat Modeling book by Adam Shostack is probably considered one of the fundamentals.
As a simplification of a whole field of expertise, please do keep in mind:
- Start small. Do not strive for completeness on the first try.
- Assign ownership and repeat. Threat models are never finished and need a maintenance rhythm.
SIG can help with such threat analysis efforts as custom consultancy services. Please reach out to your account contact if you have questions.
Filtering results for false positives: starting with Open source vulnerabilities
-
Starting with Open Source Health: Assuming that Open Source Health is enabled together with Security, you probably want to start there. Vulnerable dependencies are regularly high-risk and urgent, yet relatively easy to solve (not when it concerns major framework updates for example). Generally, updating libraries has a high return on your efforts. Also, grouping the same libraries/frameworks may be favorable because you only need to go through release notes once. This might be harder if you need to cross teams to do that. Simplified, different scenarios in which you may need to act upon possible vulnerabilities in third party code are:
- There is an easy fix or minor update (“minor” as in a small functional change, bugfix, or small increment in case of semantic versioning). Fix as soon as you can.
- There is a (partial) fix, but it is complicated or undependable/buggy. Plan deeper analysis first, estimate an effort range, and put it on the backlog for planning. Urgency for planning mostly depends on the potential severity/CVSS score, but there may be other considerations, like piggyback-updating it as part of another large update. This is especially true for transitive dependencies, where the dependency is in a frameworks own dependencies, and a framework upgrade will fix multiple issues. Plan testing effort accordingly, which may be important to anticipate in organizations where you need to “reserve” testing resources and capacity.
- There is no fix, because the owning (OSS) project is inactive, or does not consider it urgent or important enough. Also it could be that a CVE has been assigned but the owner/supplier disagrees about its exploitability and therefore does not solve (there are some examples in the Spring framework). Assess its severity first. Generally, assumptions can be made based on a library’s functionality. Escalation is expected if you are using this particular library for security-sensitive operations. (De)serialization being a notorious example. Look for alternatives, also in cases where the future of a library is uncertain. In the Open Source Health tab, indicators for these are a combination of the
 Freshness,
Freshness,  Activity, and
Activity, and  Stability estimates.
Stability estimates. - The vulnerability actually is a false positive. It could be unexploitable in the system’s particular context (e.g. because of deployment reasons)
- There is a fix, but the team cannot fix it themselves: this may be the case in organizations where the team does not have Operations under its control (e.g. where deployment or PaaS is handled by another department or [governmental] organization). In that case, the inability of the team to fix it is a direct result of this organizational choice. It could be considered an inherent “accepted risk”, but this is not completely fair. It does not fully release the team from responsibility. Corresponding to the severity of the issue, formal escalation should be considered part of the team’s/project manager’s responsibility. Impact assessment can then be done by the deployment/infra party.
Another situation could be where you are using a specific licensed version (e.g. Redhat), where you are either contractually limited by a version, the release cycle differs from the cycle of the underlying software, or forking means that vulnerabilities may (not) be applicable.
- Actual false positive: When you use frameworks where different major or minor versions have separate versioning paths, there might be version confusion in detecting vulnerabilities. For example, you could be on a latest 1.2 version, e.g. 1.2.3, but if there is a separate (serviced) 1.3.x fork where the latest version is 1.3.3, it may look like you are lagging behind, even when you are not. Upgrading would not necessarily be your required path, because it is not uncommon that (minor version) forks are developed where they are suited for a specific tech-stack. And with different tech-stacks, both exploitability and release cycles may be very different.
In case of false positives, you may contact Sigrid Support. Given the automatic resolution of versions and vulnerabilities on which Sigrid is based, we are dependent on the data quality of our data sources, but we will see what we can do for you.
-
Note on legal risks in dependencies: Any possible legal risk (e.g. GPL) is important to discuss with your legal representative/department. Legal license risks tend to apply only in specific cases, e.g. when you have modified the source code. SIG explicitly cannot help you with legal advice on this.
-
Filtering false positives (e.g. test code) by grouping findings on code location or component: To get an overview and to be able to make quick exclusions of false positives, it may be useful to order security findings by component/file see above. A file-view may expose e.g. test-code, and a component-view may show that many files may lay in a certain functional domain. As an example, deployment configurations may exist in a context of which you know that they are protected from certain security risks. This may lead to a lot of exclusions and a cleaner overview of security findings.
- Deeper analysis in the File view: In the File view you can export those findings as a spreadsheet. In case of very large lists of findings it may be advantageous to browse and filter in a spreadsheet editor, and then go back and exclude them (by groups).
Prioritizing security findings
- Sprint approaches: A tactic during sprints is to use a kind of Boy Scout approach, where you compare findings for files while you are modifying them. This tends to be efficient because you are already working in/analyzing the code. Consider making this part of the Definition of Done. See also the agile development workflow.
- Please see the Agile workflow page regarding refinement/planning for a further discussion on processing security findings in an Agile workflow.
- Prioritizing by severity is the typical approach, and this is faithful to agile practices (assuming you choose the action with the highest return first). This way you move from urgent to less urgent findings.
- Prioritizing by pattern grouping means that you may exclude or solve many findings in one go. There are indeed cases when a whole class of findings can be excluded because for some reason the findings are not applicable or can be resolved in one place. You can arrive by this grouping e.g. by using “Finding Type” (specific vulnerability) or “CWE” (more general weakness). See our section on grouping findings above.
NOTE: The tooling underlying this analysis is updated as often as possible. Therefore it may be possible that new findings are found even when code is unchanged (link to FAQ).
SIG may offer consultancy services to help you with security
Depending on your agreement with SIG, security expertise consultancy may be available. Or this can be offered as a separate consultancy effort. See also this question in the security FAQ.